利用 Canvas API 实现正方验证码的识别与自动填充
Web
技术
背景
新学期伊始,年度抢课大戏同步上映,学校的正方教务系统也迎来了前所未有的流量冲击。教务系统这个跑在 Windows 2003 的上古时期的 ASP.NET 程序的服务器自然也承受不住,在选课高峰期频频崩溃,从而也导致了用户登录的账户在选课期间频频掉线的问题。
也不得不吐槽一下这上古时期的网页的交互逻辑:教务系统在每一次掉线以后都需要重新登录。这个过程最致命的是,当登录时输入错误的情况下,用户名、密码、验证码都需要重新填写。尝试多几次,大概也会有想砸电脑的冲动,可以说是十分反人类了。。。
用户名和密码可以通过浏览器自动填充,解决了一个大问题,但验证码仍然需要手动输入,重复去输入那辣眼睛的验证码的过程,还是让人有些心塞,且很容易出错。想想这几秒钟也十分关键,关系到那些喜欢且热门的课程能否到手,所以我也产生了做一个验证码自动填充的程序的想法。
受到 eleflea/neu_filler: 自动填充东北大学教务处验证码脚本 的启发,经过半个月的研究,这个想法也变成了现实。
你可以选择以下任意一种方式使用本脚本:
- 油猴脚本:SCNU JWC Captcha filler
- 书签栏 javascript: 协议链接脚本:一键登录教务系统脚本生成器 2.0
思路
在东北大学的同学的代码启发下,了解到通过 HTML5 的 Canvas API 的 getImageData 方法可以实现对网页图片像素的读取。这里的思路大致与东北大学教务验证码填充脚本一样,不同的是这里在切割、处理单个字符的过程花了较大的功夫,具体来说可以分为以下5个步骤:
- 获取图片信息
- 将图片二值化
- 把图片中不同的字符分割出来
- 将分割的字符通过旋转的方式标准化
- 验证码的训练与识别
图片信息的获取
通过 Canvas API ,我们可以将DOM中验证码图片绘制到 canvas 中,再通过 context 对象的 getImageData 方法取出图片的像素数组备用。
获取图片信息的代码:
let img = document.getElementById("icode");
// 获取图片宽高
const { width, height } = img;
// 通过 canvas 存图片
const canvas = document.createElement("canvas");
// 设置 canvas 的宽高
canvas.width = width;
canvas.height = height;
// context
const ctx = canvas.getContext("2d");
// 把验证码绘制到canvas中
ctx.drawImage(img, 0, 0);
// 提取像素颜色数组
let imageData = ctx.getImageData(0, 0, width, height).data;
通过上述代码获取的 imageData 是一个 Uint8ClampedArray 数组对象,该数组长度是像素点个数的4倍,依次是像素点的 R, G, B, A 四个通道的大小。要注意的是,context 对象的 getImageData 函数是受到浏览器的安全策略限制的,详情可以参考API文档关于跨域图片的描述。
二值化
获取了一批样本后,发现验证码默认使用 rgb(0, 0, 153) 作为字符主体的颜色,所以这里可以通过一个简单的方式来把它区分开来。为此我新建了一个数组变量用来保存二值化图片各个像素的信息。
// 下一步,二值化
let grayImageData = [];
for (let i = 0; i < 4 * width * height; i += 4) {
// 策略,蓝色优先
let white = imageData[i] < 105 && imageData[i + 1] < 105 && imageData[i + 2] > 100;
grayImageData.push(white ? 1 : 0);
}
同时我也写了一个将新产生的二值化数据绘制到某个 Canvas 元素的函数(详见后文),效果如图:
 1103859122.png
1103859122.png
在上图中我们发现二值化后的图片中有许多噪点也一并包括了,这是因为某些噪点的颜色比较接近字符主题的颜色产生的问题。
噪点基本上都是孤立的像素,所以我们可以通过统计一个点周围的像素多少来判断这个点是不是噪点,实现的过程中,针对坐标分别设计 get, set 函数实现像素坐标与数组下标的映射。
// 获取坐标对应像素点的值
function get(x, y) {
return imageData[y * width + x];
}
// 设置像素点的值
function set(x, y, value) {
imageData[y * width + x] = value;
}
imageData.forEach((v, i) => {
// 第几行 i / width
// 第几列 i % width
let x = i % width, y = parseInt(i / width);
// console.log(x, ', ', y);
let u = get(x, y - 1) !== 0;
let d = get(x, y + 1) !== 0;
let l = get(x - 1, y) !== 0;
let r = get(x + 1, y) !== 0;
// 判断像素四周是否为孤立的像素点,没有就设置为0
// console.log(u + d + l + r);
if (v == 1 && (u + d + l + r) < 2) {
imageData[i] = 0;
}
});
参考东北大学的同学的代码,同时也想到之后的操作可能需要大量复用二值化图片,所以这里开始抽象了一个命名为 GrayImage 的数据类型,并在其原型中添加一个把二值化图片绘制到 Canvas 元素实现可视化的方法:
// 定义一个 GrayImage 数据类型
function GrayImage(width, height, dataArr) {
this.width = width;
this.height = height;
// 预先设置图片数据
if (dataArr) {
this.imageData = dataArr;
} else {
this.imageData = [];
// 初始化:所有像素点置0
for (let i = 0; i < this.width * this.height; i++) {
this.imageData.push(0);
}
}
}
// 通过 Canvas API 把二值化图形可视化
GrayImage.prototype.draw = function (ctx) {
let imgArr = new Uint8ClampedArray(4 * this.width * this.height);
for (let i = 0; i < this.width * this.height; i++) {
for (let j = 0; j < 3; j++) {
imgArr[4 * i + j] = this.imageData[i] * 255;
}
imgArr[4 * i + 3] = 255;
}
let newImageData = new ImageData(imgArr, this.width, this.height);
ctx.putImageData(newImageData, 0, 0);
};
// 获取坐标对应像素点的值
GrayImage.prototype.get = function (x, y) {
return this.imageData[y * this.width + x];
};
// 设置像素点的值
GrayImage.prototype.set = function (x, y, value) {
this.imageData[y * this.width + x] = value;
};
// 去除孤立噪点
GrayImage.prototype.removeNoise = function () {
this.imageData.forEach((v, i) => {
// 第几行 i / width
// 第几列 i % width
let x = i % this.width, y = parseInt(i / this.width);
let u = this.get(x, y - 1) !== 0;
let d = this.get(x, y + 1) !== 0;
let l = this.get(x - 1, y) !== 0;
let r = this.get(x + 1, y) !== 0;
// 判断像素四周是否为孤立的像素点,没有就设置为0
if (v == 1 && (u + d + l + r) < 2) {
this.imageData[i] = 0;
}
});
};
实现了这一步以后,当我们需要二值化图片时,直接 new 一个 GrayImage 就好了;若需要在网页将其显示出来,只需新建一个 canvas 元素,把新建元素获得的context对象传入 GrayImage 实例的 draw 方法即可,效果还是挺完美的。
 2871619751.png
2871619751.png
分割字符串
这一步是整个项目的开发过程的难点。验证码的字符经过了随机的旋转,有时候会出现粘连的状况,有时候却不会,如何应对这种变化情况,在发生粘连时将粘连字符分开,成为了一个挡在眼前的问题。
注意到验证码每个字符出现的位置比较固定,经过几天的尝试,我最终选择的方案是,先对 GrayImage 进行纵向扫描,通过统计一条扫描线上出现字符的像素点个数来做一个初步的切割,然后再根据实际的情况,通过宽度2等分、3等分、4等分的方式把粘连的字符切割开来。代码较长,就不贴了,可以在Github查看。
切割以后需要将字符四周空白部分去掉,以免影响下一步的判断,这里将去除四周空白的功能抽象为 GrayImage 数据类型的成员方法:
// 去除四周空白部分
GrayImage.prototype.removeBlank = function () {
let newImageData = [];
// 上下左右边界
let u = this.height * 2;
let d = 0;
let l = -1;
let r = 0;
// 按竖线来扫描
for (let i = 0; i < this.width; i++) {
// 统计数量,方便区分左右边界
let count = 0;
for (let j = 0; j < this.height; j++) {
if (parseInt(this.get(i, j)) === 1) {
count++;
// 上边界
if (j < u) {
u = j;
}
// 下边界
if (j > d) {
d = j;
}
}
}
// 左边界,如果l没被赋值过就设置初值,以后都不变了
if (count > 0 && l === -1) {
l = i;
}
// 右边界
if (count > 0 && r < i) {
r = i;
}
}
// 若u没有改变,说明没扫到像素点
if (u === this.height * 2) {
u = 0;
}
// 保存到数组里面
for (let i = u; i < d + 1; i++) {
for (let j = l; j < r + 1; j++) {
// console.log(this.get(j, i));
newImageData.push(this.get(j, i));
}
}
this.imageData = newImageData;
// 新的宽高
this.width = r - l + 1;
this.height = d - u + 1;
}
效果:
 423001566.png
423001566.png
随机旋转字符的标准化
到了这一步,必要的字符已经分割出来了,下一个问题随即浮出水面:教务的验证码每一个字符有30多种情况(0-9, a-z, 有的字母没有出现),比较致命的是,每个字符可能会有不同的旋转角度,这时需要判断的情况变得复杂了不少。基于这么多种情况的判断自然是一件十分消耗性能的事情,通过简单的浏览器JavaScript来判断显然不太现实,且可能会出现较大误差。从而也引出了标准化的步骤。
标准化的思路很简单,只要把所有的字符都旋转到一个固定角度就好了。
这里便扯到了位图的变换的知识,大一时懵懵懂懂地学了一点儿线性代数,很自然地联想到线性代数里面关于线性变换的内容。这里的 GrayImage 的旋转是通过线性代数的齐次坐标运算实现的,参考 这篇文章 ,结合旋转变换与平移变换以后,最终我们得到一个这样的线性变换矩阵:
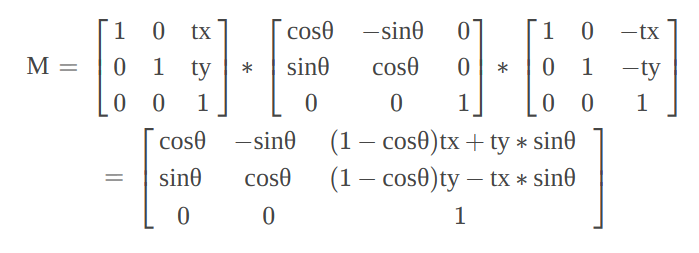 1339193320.png
1339193320.png
把原本位图的像素点坐标表示为 (x, y, 1) 的齐次坐标形式,通过这个变换矩阵的作用(矩阵乘法),得到旋转以后的点的坐标,这个过程最终表现出来的计算步骤在JS的实现如下:
function rotate(x, y, tx, ty, angle) {
let cos = Math.cos(angle);
let sin = Math.sin(angle);
let rx = Math.round(x * cos - y * sin + (1 - cos) * tx + sin * ty);
let ry = Math.round(x * sin + y * cos + (1 - cos) * ty - sin * tx);
return { rx, ry };
}
其中,x, y 为像素点原始的横纵坐标,tx, ty 为旋转中心坐标,angle为旋转角的弧度形式,角度需要 * π / 180 转换为弧度供JS内置的三角函数使用,函数返回经过旋转变换以后像素点的坐标。
接下来遍历字符所有的像素点,得到所有通过旋转矩阵作用后新的像素点的坐标。这个过程同样也封装成了 GrayImage 数据类型的成员方法,具体实现过程中,由于旋转以后可能会出现负数的坐标,不能落在可视范围内,所以这里创建了一个相对较大的“画布”(其实就是之前定义的 GrayImage 类型的对象),并将旋转后的点略微平移了一下,再调用 removeBlank 方法去除掉了“画布”中没用的空白部分,只留下旋转后的字符:
// 绕中心点旋转一定角度,返回一个旋转后的GrayImage
GrayImage.prototype.rotate = function (deg) {
// 创建一个 30 x 30 的临时画布
let grayChar = new GrayImage(30, 30);
// 开始旋转,像素矩阵需要经过旋转矩阵变换得到新的矩阵
let tx = Math.round(this.width / 2);
let ty = Math.round(this.height / 2);
for (let i = 0; i < this.width; i++) {
for (let j = 0; j < this.height; j++) {
let axis = rotate(i, j, tx, ty, deg * Math.PI / 180); // 旋转角,需要转换为弧度制
// console.log(i, j, axis);
// +8是为了把旋转后的图形平移到可视范围,方便进一步切割
grayChar.set(axis.rx + 8, axis.ry + 8, this.get(i, j));
}
}
// 返回之前去除多余空白
grayChar.removeBlank();
return grayChar;
//
// 旋转角度函数,基于齐次坐标的线性变换
// http://blog.csdn.net/csxiaoshui/article/details/65446125
//
function rotate(x, y, tx, ty, angle) {
let cos = Math.cos(angle);
let sin = Math.sin(angle);
let rx = Math.round(x * cos - y * sin + (1 - cos) * tx + sin * ty);
let ry = Math.round(x * sin + y * cos + (1 - cos) * ty - sin * tx);
return { rx, ry };
}
}
那么怎么通过旋转使得字符标准化呢?参考《常见验证码的弱点与验证码识别》,这里也使用了里面的思路:通过从逆时针25度到顺时针25度依次的旋转,在每次旋转中获得旋转后图形的宽度,取宽度最小的字符作为最终结果返回。
为了减小性能损失,这里的步进值是2度(在实际的测试中,对于 Chromium 的 V8 引擎来说,这种事情对于它的性能并没有多大的影响):
// 获得标准化字符(把歪了的字符转回来)
GrayImage.prototype.normalize = function () {
let charList = [];
let minIndex = -1;
let minWidth = this.width;
// 从-25度旋转到25度,比较宽度,找到宽度最小的一个
for (let i = -25; i <= 25; i += 2) {
let newChar = this.rotate(i);
charList.push(newChar);
if (newChar.width < minWidth) {
minWidth = newChar.width;
minIndex = charList.length - 1;
}
}
if (minIndex === -1)
return this;
// console.log(minWidth, minIndex);
return charList[minIndex];
};
打印出经过旋转标准化后的图形,看起来大体上没有问题,但总给人一种“千疮百孔”的感觉。
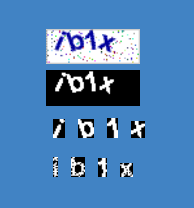 3169189188.png
3169189188.png
起初我以为是JS引擎中三角函数的计算精度问题,但后来经过统计发现,像素点并没有缺少,经过搜索了解到,这一步其实引出了位图变换的插值问题。(感觉像是打开了一个新的巨坑,以前从未注意过)
看到知乎某个回答关于这个话题的一句话:
自然科学中只要涉及到 —连续的物理信号采样和表示为离散信号,再重建为连续信号— 这一过程的,插值都是重建过程中的主要手段之一。
但是我想做的只是浏览器端的验证码识别哇,形状没差就行,所以图形的处理就到此为止吧。
样本训练与识别的实现
由于目前掌握的知识有限,加之浏览器端不可能跑过于复杂的脚本,所以最终我采用的是较为简单方便的比较 Levenshtein distance (莱文斯坦距离,也叫编辑距离) 的手段来实现。这里将处理后的验证码字符的 ImageData 数组与收集的样本一一计算莱文斯坦距离,找到样本中最接近目标的一个字符,将这个字符的值作为返回结果。
这时候这个算法的性能就取决于算法本身的开销以及样本的数量了,好在正方的验证码本身并没有太多像素点,相对还是很好判断的。至于样本的数量可能会比较大的问题,先看着办吧,遇到瓶颈了再考虑继续优化。
Levenshtein distance 算法本身在网上有许多实现,经过对比之后我选择了一个目前性能表现最好的一个库 gustf/js-levenshtein, 顺便用 Node 的 Express 框架实现了一个简单的人工打码样本收集器,将样本的宽高,对应字符,二值化数组数据保存在一个 SQLite 数据库中。
 1989234132.png
1989234132.png
大概收集了 1500 多条的数据,识别的精度看起来还不错,时间消耗大约在 200ms 左右,具体多少没有严格测试,但实际使用中,绝大部分图片都可以一次识别通过,偶尔需要两次,极少数情况是3次通过的。
后来我继续字符的宽度将样本做了一个简单的分类,减小需要进行比较的样本数量,效果还是很显著的,识别的时间消耗降低到了 50-100ms 左右,基本可以投入使用了。
在实践的过程中,另外我也抽象了一个样本集合的对象出来,主要代码如下:
// charList 样本库数据对象
let charList = {
// 按照宽度分类的字符列表
charQueueList: null,
// 从服务器下载样本集
download: async function () {
try {
let { success, data, version } = await fetchURL("/chars/get");
if (!success) throw "error";
// 保存样本集的数组
let charList = data;
// 按照宽度来分类样本集
this.charQueueList = [];
charList.forEach((v) => {
// 创建二维数组
if (!this.charQueueList[v.width]) {
this.charQueueList[v.width] = [];
}
this.charQueueList[v.width].push(v);
});
// 存入缓存
storage.set("charListVersion", version);
storage.set("charList", this.charQueueList);
// 开始处理
return { version };
} catch (e) {
return Promise.reject(e);
}
},
// 找到与传入的 GrayImage 最接近的字符
recognize: function (char) {
console.log(char);
let distance;
let c;
// 取出宽度对应的执行队列
let queue = this.charQueueList[char.width];
// console.log(queue);
for (let i = 0; i < queue.length; i++) {
let d = levenshtein(char.imageData.join(""), queue[i].data);
if (distance === undefined || d < distance) {
distance = d;
c = queue[i];
}
if (distance < 4) break;
}
return { distance, char: c };
},
}
至此,关键的核心功能已经实现,剩下要做的就是将其嵌入真正的教务系统中了,为此我打包了一个油猴脚本,点击直达:SCNU JWC Captcha filler
为了方便不方便整油猴脚本的小伙伴,我还另外做了一个通过浏览器书签栏加载的版本,并且写了个简单的界面:�一键登录教务系统脚本生成器 2.0 (这种方式涉及到了一些较为危险的操作,例如从我的服务器下载脚本到浏览器端执行,若不信任请勿使用)
后记
我在做这个脚本的过程收获颇多,了解到了许多浏览器API、DOM对象的细节,同时也感受到了自己基础的薄弱之处,日后得多花一些时间精力提升编程的内功。
本文涉及的所有代码均上传到了Github,需要的伙伴可以参考参考。
Github:https://github.com/zgq354/zf_captcha_filler
参考: