HTML5 File API 配合 Web Worker 计算大文件 SHA3 Hash 值
Web
技术
这学期的安全学课程有个作业,内容是写一个软件实现 SHA3 Hash 值的快速计算。想一想老师这么安排,大致上也有一种推广新的密码学算法的意图。既然希望应用起来,天然跨平台的 Web 显然是一项非常具备优势的技术,想到 HTML5 有定义网页与文件系统交互的 File API 标准,而且很多浏览器已经实现,基于浏览器端,实现一个 Sha3 的在线哈希岂不是更好?
根据文档,浏览器端的 FileReader 对象提供了 readAsArrayBuffer 的方法,可以将文件的二进制内容读取到 ArrayBuffer 字节数组对象中,然后就能通过JS去操作包含文件内容的字节数组,这也让浏览器端实现文件哈希提供了可能。当然,实际上也是可以实现的,这里分为两个部分来介绍这个过程。
文件内容的读取
首先当然是想办法得到这个文件在 JavaScript 环境中的表达,浏览器 JS 环境中,文件抽象为 File 对象,它可以通过 DOM 提供的 FileList 接口拿到通过表单文件域得到,也可以从拖放��事件中拿到,下面的是通过表单的 FileList 来获得的代码。
const selectedFile = document.getElementById('input').files[0];
File 对象本身只代表文件本身和其中部分元数据,对于文件的内容,浏览器 JS 是通过 FileReader 等对象来操作(读取)的。FileReader 的用法也十分简单,需要注意的是,它是异步的API,所以需要绑定一下回调函数,然后调用 readAsArrayBuffer 让浏览器发起文件读取请求:
let reader = new FileReader();
reader.onloadend = function () {
console.log(reader.result);
}
reader.readAsArrayBuffer(selectedFile);
接下来浏览器将会通过系统调用把 selectedFile 变量所指代的 File 对象的内容读取到内存中。这里存在一个问题,载入文件的时候,JS引擎需要向内存申请一块与文件内容等大的内存空间来存放这个文件的内容,显然,在内存有限的前提下,直接读取的做法是处理不了太大的文件的。这里我们需要换一下思路。从哈希算法角度来说,哈希的过程,实际上也是把原文加上 padding 之后以一个个分组为单位来进行的,也就意味着,我们可以在输出最终结果之前,分批读取原文,输入哈希函数,最后从哈希函数的最终状态中读取结果。
立足于这个想法,只要我们在浏览器端实现文件的部分读取的话,这一套流程就能打通了,需求也得以实现。正好,在浏览器的 JS 环境中,File 对象的原型是名为 Blob 的对象,Blob 的定义是一段不可变的原始二进制数据,在浏览器JS的环境中,文件被抽象成了 Blob 所描述的一块只读的二进制数据。在 Blob 对象中,实现了一个 Blob.slice([Range]) 方法,执行这个方法返回的是一个新的 Blob 对象,这个新的 Blob 所代表的是方法执行时通过 Range 参数指定的部分,类似“分割”的感觉。File 对象继承了 Blob 的所有方法,所以同样地,我们也可以通过 File.slice() 方法实现返回一个只代表其中一部分内容的新的 File 对象。接下来,我们再使用 FileReader 来读取这个新的 File 对象,就能让浏览器底层通过系统调用读取相应 Range 的字节载入到内存中了。
回到我们分批读取文件的需求。再往上层去看的话,分批去读取文件内容参与哈希,是一个从前到后的连续读取的 pattern。这样的工作模式,抽象起来类似于流(Stream)的机制。类似我们平时在 C++ 用到的 iostream, fstream 等等,所谓的 Stream,本质上也是一种按顺序读取的机制的具体实现。这种机制在浏览器JS引擎中所对应的,是在新的 Web 标准所定义的 Stream API 标准。Node.js 的 fs 模块已经实现了这样的机制,但浏览器的 FileReader 暂时并没有提供一个用 ReadableStream 接口实现文件流的方法,鉴于此,我们可以模仿 ReadableStream 接口的工作模式,自己封装一个类似的功能。
与 C++ 的 fstream 等不一样的是,JS的流中,传输数据的单位是 "chunk",一个 chunk 一般以若干个原子单位(也就是byte)组成,很少有一次只传��输单个 byte 的情况,所以这里并不需要额外定义 buffer,但需要留意一下每个 chunk 默认的大小。关于 chunk 的具体介绍,可以参考chunk 在 WHATWG 的定义。
文件读取函数的实现,我这里是通过一个状态变量记录文件当前读取到的位置(下一次读取这个文件的偏移量),返回一个对应的闭包交给调用者处理。由于文件读取是异步操作,在闭包中,通过返回 Promise 来传递异步结果,调用时直接 await 这个闭包函数就好了。每一次调用,就返回一个 chunk。这里约定 chunk 占用 1M 大小的空间,当文件读取到最后,根据定义,最后一个 chunk 的大小为文件大小 mod chunkSize,符合我们的预期,具体的函数的代码如下。
function getStreamReader(file, chunkSize = 1024 * 1024) {
let reader = new FileReader();
let offset = 0;
return function () {
return new Promise(function (resolve, reject) {
if (offset >= file.size) return resolve(null);
reader.onloadend = function () {
resolve(reader.result);
offset = offset + chunkSize;
}
reader.onerror = reject;
reader.readAsArrayBuffer(file.slice(offset, offset + chunkSize));
});
}
}
有了 Promise,我们可以利用 async/await 特性,优雅地迭代这个“流”。
const selectedFile = document.getElementById('input').files[0];
console.log(selectedFile);
let read = getStreamReader(selectedFile);
(async () => {
let chunk;
while (chunk = await read()) {
console.log(chunk);
}
})();
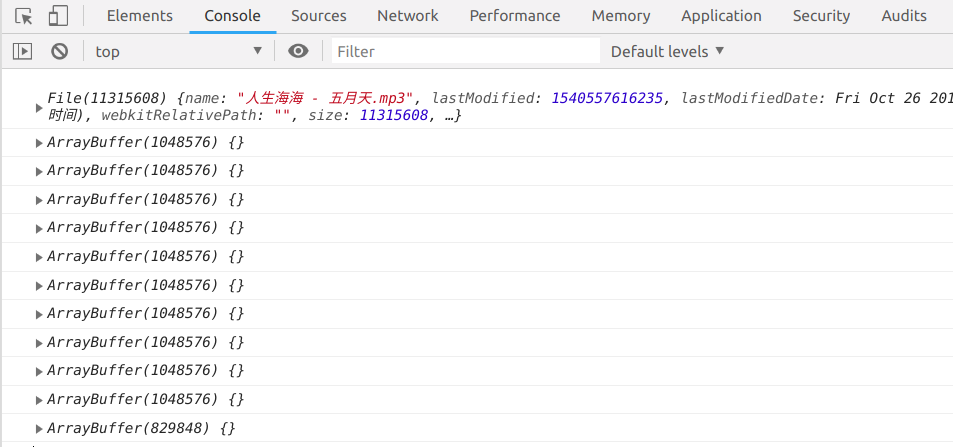 分 chunk 读取的结果
分 chunk 读取的结果
接下来直接处理每一次返回的 chunk 即可。
计算 Hash 值
实现了文件的输入和分 chunk 读取,针对算法的整体输入的环�境其实已经创造好了,接下来就是如何利用这些原料生产出需要的哈希值。在此之前,已有前人填上了这部分的坑,由于暂时没有时间,这里也直接调用前辈做好的库吧(emn178/js-sha3),以后有时间有心情了再好好研究一下如何实现。
在前辈的库中,关于分块的哈希的算法,封装之后,提供了两个主要的方法,一个是 update(),另一个是 hex(),这里都用上了。摘要长度我选择了256位,所以代码变成了:
const selectedFile = document.getElementById('input').files[0];
let read = getStreamReader(selectedFile);
(async () => {
let chunk;
let hasher = sha3_256.create();
while (chunk = await read()) {
hasher.update(data);
}
console.log('result', hasher.hex());
})();
可以说,有前辈的助力,整个过程变得非常简单方便(逃
这里又衍生了一个问题,JavaScript 的语句是单线程运行的,在 JavaScript 对一个 chunk 进行运算的时候,浏览器是做不了 UI 重排重绘等一系列事情的,若这个过程的时间消耗太久,超过了肉眼对刷新的感知的话,页面会给人一种卡顿感。虽然说这个小 Demo 不怎么需要关注 UI 的性能问题,假如这个技术应用到了实际的网站呢?(比如说网盘网站的秒传功能的实现)
这里有两种选择,一种是适当地调整 Chunk 的大小,使其计算的过程耗时不超过肉眼能感知的刷新时间;另一种是,利用 Web Worker 新建一个JS线程,把计算哈希的任务交给它,然后只要等待结果就好了。第一种方法很好实现,把 chunk 的大小设为 1M,基本没有什么问题。但,毕竟第二种方法是新东西,还是要尝试一下的嘛~
搜索发现,有一个 想法 和我不谋而合,所以这里也参考了作者的思路。
这里需要重点解决的是主线程与 Worker 的通信问题,浏览器主线程提供了 worker.postMessage 方法与 window.onmessage 事件来实现通信。起初我还有点担心把 Chunk 传入 Worker 会有内存拷贝的多余开销,后来发现浏览器 API 提供的 Transferable 对象的设定,打消了我这一份顾虑,向 Worker 线程传递文件,理论上是可行的。
不想把 Worker 的文件独立开,所以我把 Worker 的代码内联在了一个 script 元素,通过创建 Blob 对象,然后 createObjectURL 的方式来运行这个 Worker,具体的过程参考了 这篇文章,Worker 的代码如下:
let hasher;
self.addEventListener('message', function (e) {
let msg = e.data;
switch (msg.type) {
case 'url':
let { url } = msg;
url = url.substring(0, url.lastIndexOf('/') + 1);
importScripts(url + 'sha3.js');
// init
hasher = sha3_256.create();
break;
case 'update':
hasher.update(msg.input);
self.postMessage({
type: 'success'
});
break;
case 'result':
self.postMessage({
type: 'result',
result: hasher.hex(),
});
self.close();
break;
default:
break;
}
}, false);
在这其中踩了一个小小的坑,内联的 Web Worker 不能用相�对路径 importScript,需要传入完整的URL地址,所以在代码的实现中,主线程通过 postMessage 的方式向 Worker 线程传入了一个 URL 来做初始化。
操作方面,继续通过生成返回 Promise 闭包的方式提供操作 Worker 的接口:
// load Web Worker
let blob = new Blob([document.querySelector("#worker").textContent]);
let workerUrl = window.URL.createObjectURL(blob);
function getWorker() {
let worker = new Worker(workerUrl);
worker.postMessage({
type: 'url',
url: location.href,
});
return {
updateData: function (data) {
worker.postMessage({
type: 'update',
input: data
}, [data]);
return new Promise(function (resolve, reject) {
worker.onmessage = resolve;
});
},
getResult: function () {
worker.postMessage({
type: 'result'
});
return new Promise(function (resolve, reject) {
worker.onmessage = function (e) {
msg = e.data;
resolve(msg.result);
};
});
}
};
}
最后调用的代码稍微改一改就好了:
const selectedFile = document.getElementById('input').files[0];
let read = getStreamReader(selectedFile);
let worker = getWorker();
(async () => {
let chunk;
while (chunk = await read()) {
await worker.updateData(data);
}
console.log('result', await worker.getResult());
})();
在此基础上,为了操作的友好,我也另外加入了一些界面的元素,还有文件拖放的支持,最终效果可以在这里预览:https://zgq354.github.io/sha3/
2G的文件拖进去,全程这个页面的JS引擎每一个线程都只有几MB的内存占用,感觉效果还是很可以的~
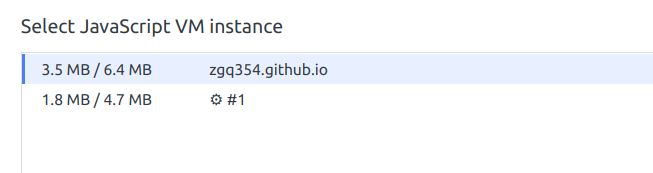 内存占用
内存占用
性能方面,在我的 Core i5 6200U 小笔记本上,大概在 20MB/s 上下,可以接受。
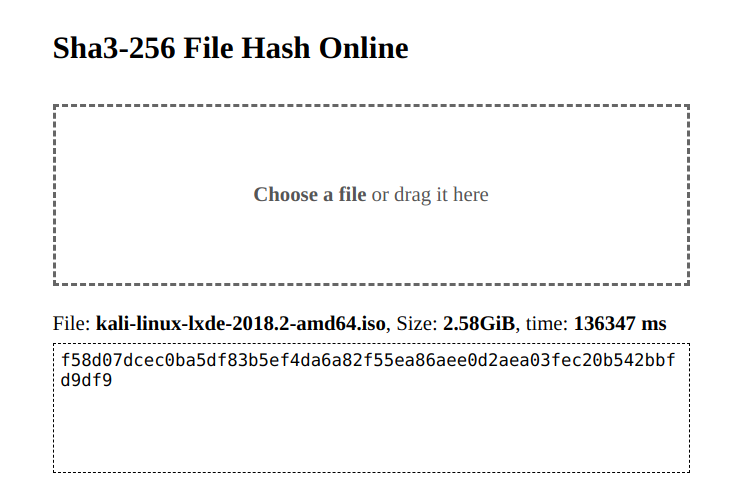 性能
性能
总结
讨论了这么多,其实这里介绍的整个过程早已被开发 sha3-js 的前辈实现了,甚至 ta 几乎把各种相关的密码学函数都做了一遍(SHA3-256 File Checksum Online),有种重复造轮子的意味。不过,在我的角度来看,别人封装好的东西,在自己不了解的情况下,用着始终都在受限制。在时间精力允许的情况下,试着主动探索一下,可以收获很多。这一次的亲身体验,至少在第一印象上,让我对浏览器端处理大文件的性能�方面有了更多的信心。
看着 File API 和 Stream 相关的定义,发现,现在的 Web 也渐渐地拥有原本只有客户端才能实现的能力,以 Web 的跨平台优势,未来,在系统架构中说不定会出现一种类似“浏览器层”这样的抽象层?
参考
- html5 - javascript FileReader - parsing long file in chunks - Stack Overflow
- File | MDN
- Streams API | MDN
- WritableStream | MDN
- A Guide to Faster Web App I/O and Data Operations with Streams - Blog | SitePen
- ArrayBuffer - ECMAScript 6入门
- Streams Standard
- The Basics of Web Workers - HTML5 Rocks
- WEB WORKER配合FILE API,加速前端秒传读取MD5