在网页中提取链接的“三板斧”
Web
技术
宿舍有个树莓派常年开着吃灰,装了 Transmission 用来挂种子。由于挂下来的资源大部分都是视频类型,所以也不必下载下来。于是我配置了一个开了 autoindex 的 Nginx 服务器,在校园网内,直接通过一个内网的 URL 来实现资源的访问。
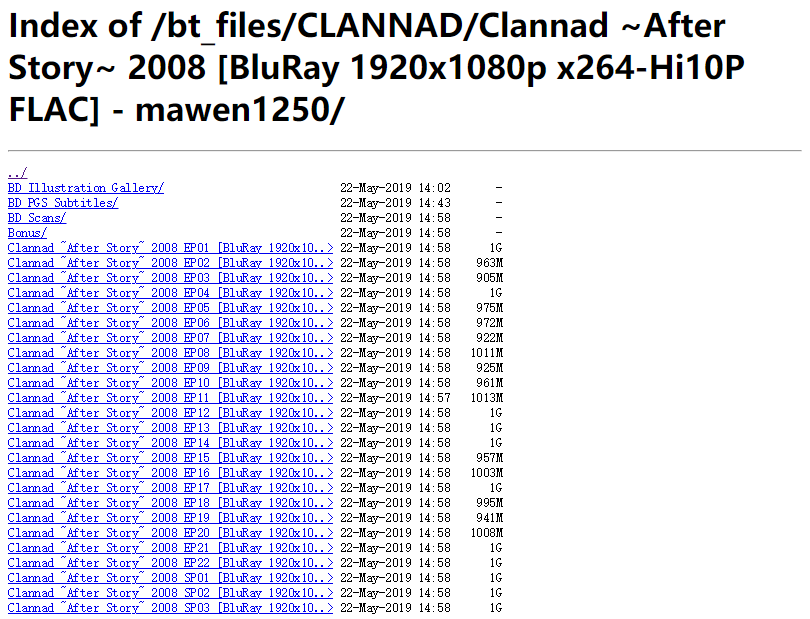 源网页
源网页
最近开始接触纸片人,有时候想把一个文件夹里面的剧集加到播放列表,几十个视频一个个添加显然是一件很麻烦的事情。观察发现,PotPlayer 可以批量添加 URL,所以说,我只要把所有的链接一起导出、添加就好了。
面对这个需求,一开始不假思索地就有了这样的想法:先用 document.querySelectorAll 把所有的 a 标签拿出来,然后循环遍历,再进行过滤,收集数据等操作,写出的代码大概�是这样的(直接在浏览器控制台运行的 JavaScript):
var list = document.querySelectorAll("a");
var result = "";
for (var i = 0; i < list.length; i++) {
if (list[i].herf.indexOf("mkv") !== -1) { // 筛选
result += list[i].href + "\n"; // 收集结果
}
}
console.log(result);
原本我以为这次还是和往常一样,但恰好昨天看了一点 《函数式编程思维》,我看待这个问题的角度也开始发生了变化。
这本书介绍了函数式编程范式与命令式编程的差别。命令式的编程的思维,需要我们定义状态,然后也要自己去管理状态的保存,迭代等等细节。当底层的状态的操作和需要解决的问题的逻辑混在一起以后,因为人脑把控的有限,程序出错的可能性也大大增加。函数式的编程的思维,程序员只需专注于更高层次的业务场景的抽象上,那些琐碎的控制,则交给 runtime 去处理和优化。这个过程对于脑力的解放,就如类似 Java 的有垃圾回收机制的语言让 runtime 接管了复杂容�易出错的内存管理一般。
对于我目前面临的这个问题,抽象来说,是一种列表数据的处理,所以关键是一个列表的数据结构。从函数式的角度来看,上面的整个过程,可以归纳为书中提到的操作列表的“三板斧” —— 筛选(filter)、映射(map)、折叠(fold)/化约(reduce)。
而这“三板斧”各自的具体操作,则可以通过匿名函数的方式传入。
JavaScript 本身的列表对象也提供了体现函数式思想的 API,对于列表类型 Array 本身也封装了“三板斧”里面涉及到的方法:
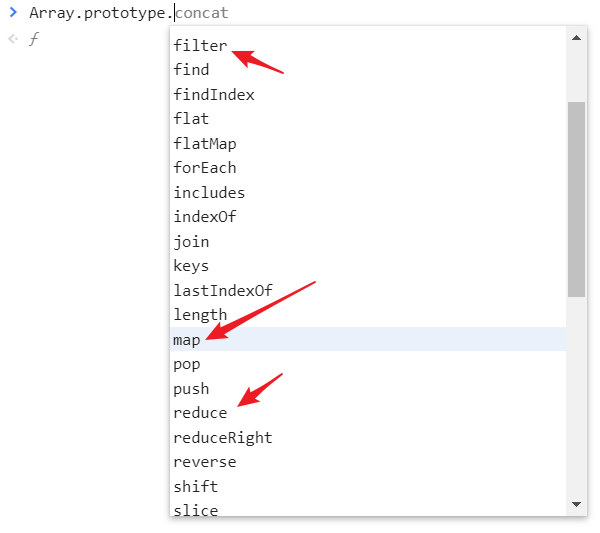 Array.prototype
Array.prototype
整个过程也可以按照这个思路进行:
-
拿到数据源的列表这里通过浏览器的 Selector API 将 DOM 中所有的链接元素提取出来,由于 document.querySelectorAll 方法返回的对象不是Array 数组类型,所以这里通过 ES6 的
...扩展语法,将它变为一个真正的 JS 数组。[...document.querySelectorAll('a')]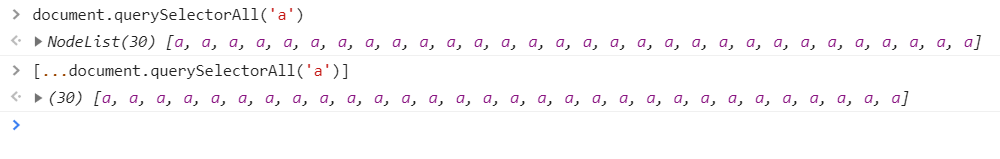 594789308.png
594789308.png -
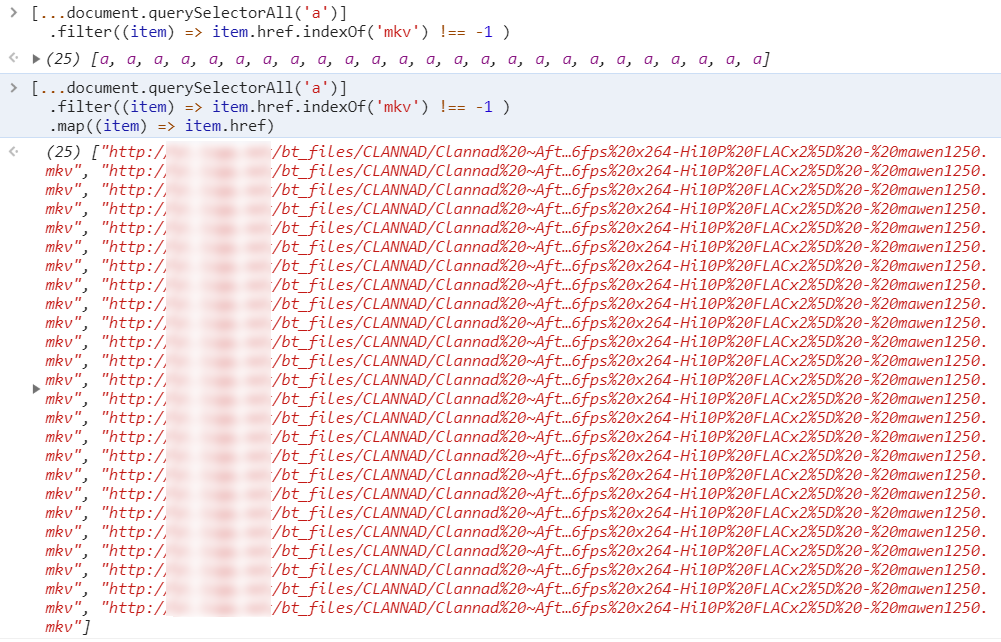
过滤对这个数组执行 filter 方法,传入一个判断函数,这里的判断条件是,链接是否包含 "mkv"(代表视频格式的后缀)。
[...document.querySelectorAll('a')] .filter((item) => item.href.indexOf('mkv') !== -1 )我们可以看到,经过这一段处理,返回一个过滤后只剩下 25 个元素的数组。
 3769568929.png
3769568929.png -
将链接元素映射为链接字符串这里的数组的元素全都是 DOM 中的链接元素节点,但我要的是字符串,所以这里需要通过映射(map)的方式把元素转为链接,链接在这里表现为 a 元素的 href 属性。
[...document.querySelectorAll('a')] .filter((item) => item.href.indexOf('mkv') !== -1 ) .map((item) => item.href)数组执行 map 方法以后,返回的是每一个元素经过映射函数之后的数组。
 981786108.png
981786108.png -
获得最终结果:由于这里是一个数组,我们最后要的是一个可以复制出来的字符串,所以最后还要进行一个化约(reduce)的操作。JS 数组的 reduce 方法至少需要传入一个接收两个参数的累积函数,每一步累积的变量 accumulator,代表累积过程的当前元素 currentValue,由于这里是给链接字符串之间添加一个换行符,所以累积函数可以写成:
function (accumulator, currentValue) { return accumulator + '\n' + currentValue; }简化为箭头函数的形式,则是
(accumulator, currentValue) => accumulator + '\n' + currentValue然后得到最终的代码:
[...document.querySelectorAll('a')] .filter((item) => item.href.indexOf('mkv') !== -1 ) .map((item) => item.href) .reduce((accumulator, currentValue) => accumulator + '\n' + currentValue)reduce 方法执行时,会一个个遍历列表的元素,按照函数所描述的规则去累积结果。
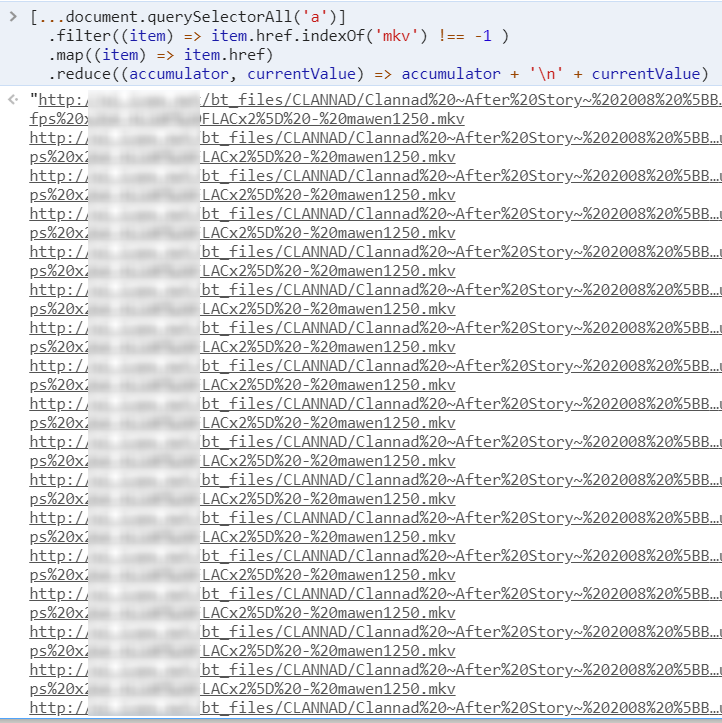 1525960015.png
1525960015.png
如此简单几步,我们完全不用去思考循环的变量应该怎么写,整个代码的演化过程,也从一点点修改和调试代码,变成解决问题的步骤的一行行增加,人脑在实际问题和计算机指令之间翻译的开销让步于成本更低的 runtime,可以说是十分地舒服了。借鉴这样的思路,可以更优雅快速准确地解决很多类似的甚至更加复杂的问题。
把结果复制到播放器,愉快地开启新一轮的补番之旅~
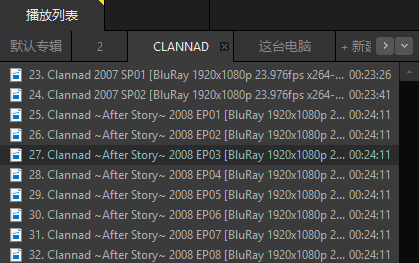 1250825548.png
1250825548.png
写到最后,突然想起了 Unix 命令行的管道机制。在命令行下我们常用 cat grep awk head tail 之类的命令,程序与程序之间,通过统一的标准输入输出流和“管道”,以一个个 byte 进行信息的传递,或许也可以说是�某种意义上的“函数式编程”?